Q&A 7 Challenge Yourself
Now that you’ve imported and queried real-world data, try these exercises:
7.1 Multi-course students
Goal: Write a query to list all students who are enrolled in more than one course.
SQL Code:
SELECT s.name, COUNT(*) AS courses_taken
FROM grades g
JOIN students s ON s.id = g.student_id
GROUP BY s.id, s.name
HAVING COUNT(*) > 1
ORDER BY courses_taken DESC, s.name;✅ Answer Key (click to expand)
MariaDB [cdi_realworld]> SELECT s.name, COUNT(*) AS courses_taken
FROM grades g
JOIN students s ON s.id = g.student_id
GROUP BY s.id, s.name
HAVING COUNT(*) > 1
ORDER BY courses_taken DESC, s.name;
+---------------+---------------+
| name | courses_taken |
+---------------+---------------+
| Alice Example | 2 |
| Charlie Data | 2 |
| Diana Learner | 2 |
+---------------+---------------+
3 rows in set (0.012 sec)7.2 Top-performing course
Goal: Find which course has the highest proportion of A grades.
SQL Code (ratio table):
SELECT c.course_name,
SUM(CASE WHEN g.grade = 'A' THEN 1 ELSE 0 END) AS num_A,
COUNT(*) AS total,
SUM(CASE WHEN g.grade = 'A' THEN 1 ELSE 0 END) / COUNT(*) AS a_ratio
FROM courses c
JOIN grades g ON c.id = g.course_id
GROUP BY c.course_name
ORDER BY a_ratio DESC;✅ Answer Key (click to expand)
+--------------------+-------+-------+---------+
| course_name | num_A | total | a_ratio |
+--------------------+-------+-------+---------+
| SQL Basics | 2 | 3 | 0.6667 |
| Data Science | 1 | 2 | 0.5000 |
| Python Programming | 1 | 2 | 0.5000 |
+--------------------+-------+-------+---------+
3 rows in set (0.011 sec)Python Starter:
query = """
SELECT c.course_name,
SUM(CASE WHEN g.grade = 'A' THEN 1 ELSE 0 END) AS num_A,
COUNT(*) AS total
FROM courses c
JOIN grades g ON c.id = g.course_id
GROUP BY c.course_name
"""
df = pd.read_sql(query, engine)
df["A_ratio"] = df["num_A"] / df["total"]
print(df.sort_values("A_ratio", ascending=False))
course_name num_A total A_ratio
2 SQL Basics 2.0 3 0.666667
0 Data Science 1.0 2 0.500000
1 Python Programming 1.0 2 0.5000007.3 Grade distribution for one student
Show all grades for a given student (e.g., Alice Example) across their courses.
SQL Code
SELECT s.name, c.course_name, g.grade
FROM grades g
JOIN students s ON s.id = g.student_id
JOIN courses c ON c.id = g.course_id
WHERE s.name = 'Alice Example'
ORDER BY c.course_name;✅ Answer Key (click to expand)
+---------------+--------------+-------+
| name | course_name | grade |
+---------------+--------------+-------+
| Alice Example | Data Science | A |
| Alice Example | SQL Basics | B |
+---------------+--------------+-------+
2 rows in set (0.011 sec)Python Starter:
7.4 Export to CSV
Export the grade distribution per course into a CSV file and optionally visualize it.
SQL Code
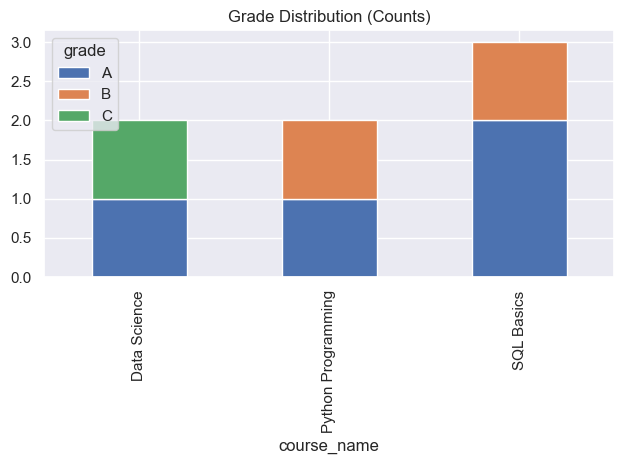
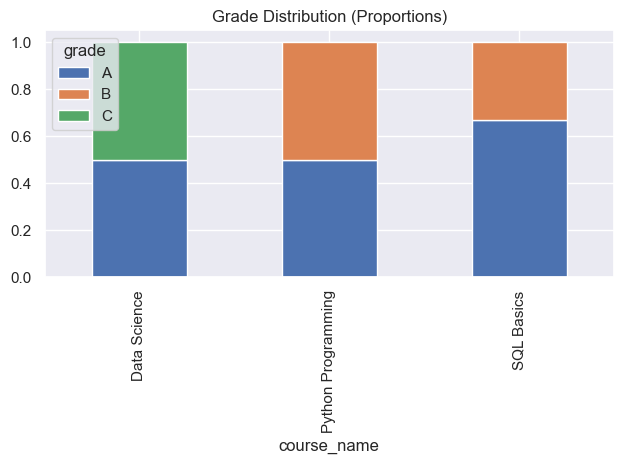
SELECT c.course_name, g.grade, COUNT(*) AS count
FROM courses c
JOIN grades g ON c.id = g.course_id
GROUP BY c.course_name, g.grade
ORDER BY c.course_name, g.grade;✅ Answer Key (click to expand)
+--------------------+-------+-------+
| course_name | grade | count |
+--------------------+-------+-------+
| Data Science | A | 1 |
| Data Science | C | 1 |
| Python Programming | A | 1 |
| Python Programming | B | 1 |
| SQL Basics | A | 2 |
| SQL Basics | B | 1 |
+--------------------+-------+-------+
6 rows in set (0.004 sec)Python Starter:
import os, pandas as pd, matplotlib.pyplot as plt
os.makedirs("data", exist_ok=True)
q = """
SELECT c.course_name, g.grade, COUNT(*) AS count
FROM courses c
JOIN grades g ON c.id = g.course_id
GROUP BY c.course_name, g.grade
ORDER BY c.course_name, g.grade;
"""
df = pd.read_sql(q, engine)
df.to_csv("data/grade_distribution.csv", index=False)
print("✅ Saved data/grade_distribution.csv")
# Stacked bar: counts
wide = df.pivot(index="course_name", columns="grade", values="count").fillna(0)
wide.plot(kind="bar", stacked=True, title="Grade Distribution (Counts)")
plt.tight_layout(); plt.show()
# Stacked bar: proportions
prop = wide.div(wide.sum(axis=1), axis=0)
prop.plot(kind="bar", stacked=True, title="Grade Distribution (Proportions)")
plt.tight_layout(); plt.show()✅ Saved data/grade_distribution.csv