Q&A 6 🌍 How do you work with real-world data in SQL?
6.1 Explanation
Learning SQL is more powerful when you use real datasets instead of tiny toy examples. By importing structured data (CSV files, spreadsheets, or exports from real systems), you can practice filtering, joining, and visualizing results just like in real-world projects.
In this Q&A, we’ll simulate a student–courses–grades dataset. We’ll create tables, import data, run analytical queries, and visualize the results in Python.
⸻
6.2 Example Dataset (CSV)
- students.csv
id,name,email,enrolled_date
1,Alice Example,alice@example.com,2025-08-10
2,Bob Tester,bob@test.com,2025-08-11
3,Charlie Data,charlie@datainsights.com,2025-08-15
4,Diana Learner,diana@learn.org,2025-08-20- courses.csv
id,course_name
1,Data Science
2,SQL Basics
3,Python Programming- grades.csv
student_id,course_id,grade
1,1,A
1,2,B
2,2,A
3,1,C
3,3,B
4,2,A
4,3,A6.3 SQL/MySQL Code
-- Real-world exercise uses its own database to avoid clobbering earlier chapters
-- scripts/realworld_data.sql
-- DB: cdi_realworld
DROP DATABASE IF EXISTS cdi_realworld;
CREATE DATABASE cdi_realworld;
USE cdi_realworld;
-- (Re)create tables
CREATE TABLE students (
id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
enrolled_date DATE
);
CREATE TABLE courses (
id INT PRIMARY KEY,
course_name VARCHAR(100)
);
CREATE TABLE grades (
student_id INT,
course_id INT,
grade CHAR(1),
FOREIGN KEY (student_id) REFERENCES students(id),
FOREIGN KEY (course_id) REFERENCES courses(id)
);
-- Load CSVs (run MySQL client with --local-infile=1; use absolute paths)
LOAD DATA LOCAL INFILE '/Users/tmbmacbookair/Dropbox/GITHUB_REPOs/cdi-database-management/data/students.csv'
INTO TABLE students
FIELDS TERMINATED BY ',' ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(id, name, email, enrolled_date);
LOAD DATA LOCAL INFILE '/Users/tmbmacbookair/Dropbox/GITHUB_REPOs/cdi-database-management/data/courses.csv'
INTO TABLE courses
FIELDS TERMINATED BY ',' ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(id, course_name);
LOAD DATA LOCAL INFILE '/Users/tmbmacbookair/Dropbox/GITHUB_REPOs/cdi-database-management/data/grades.csv'
INTO TABLE grades
FIELDS TERMINATED BY ',' ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(student_id, course_id, grade);
-- 4) Sanity checks
SELECT COUNT(*) AS n_students FROM students;
SELECT COUNT(*) AS n_courses FROM courses;
SELECT COUNT(*) AS n_grades FROM grades;
-- 5) Quick integrity check (should return rows)
SELECT s.name, c.course_name, g.grade
FROM grades g
JOIN students s ON s.id = g.student_id
JOIN courses c ON c.id = g.course_id
ORDER BY s.name, c.course_name;
-- 6) Example analytics
-- Students per course (includes 0 if you switch to LEFT JOIN)
SELECT c.course_name, COUNT(g.student_id) AS total_students
FROM courses c
LEFT JOIN grades g ON c.id = g.course_id
GROUP BY c.course_name
ORDER BY total_students DESC;
-- Grade distribution by course
SELECT c.course_name, g.grade, COUNT(*) AS count
FROM courses c
JOIN grades g ON c.id = g.course_id
GROUP BY c.course_name, g.grade
ORDER BY c.course_name, g.grade;6.4 Python Code (pandas + matplotlib)
# Install once:
# pip install pandas SQLAlchemy pymysql matplotlib seaborn
from sqlalchemy import create_engine
import pandas as pd
import matplotlib.pyplot as plt
# Optional: nicer defaults
try:
import seaborn as sns
sns.set_theme()
except Exception:
sns = None
# ⬇️ Connect to your real-world DB
engine = create_engine("mysql+pymysql://root:@localhost/cdi_realworld")6.5 Students per course (counts)
q_counts = """
SELECT c.course_name, COUNT(g.student_id) AS total_students
FROM courses c
LEFT JOIN grades g ON c.id = g.course_id
GROUP BY c.course_name
ORDER BY total_students DESC;
"""
df_counts = pd.read_sql(q_counts, engine)
display(df_counts) # in notebooks
# --- matplotlib ---
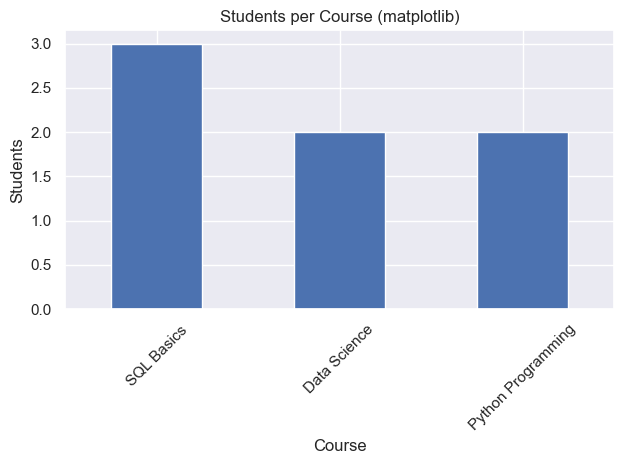
ax = df_counts.plot(kind="bar", x="course_name", y="total_students", legend=False)
ax.set_title("Students per Course (matplotlib)")
ax.set_xlabel("Course")
ax.set_ylabel("Students")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()| course_name | total_students | |
|---|---|---|
| 0 | SQL Basics | 3 |
| 1 | Data Science | 2 |
| 2 | Python Programming | 2 |
# --- seaborn (optional) ---
if sns:
ax = sns.barplot(data=df_counts, x="course_name", y="total_students")
ax.set_title("Students per Course (seaborn)")
ax.set_xlabel("Course")
ax.set_ylabel("Students")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()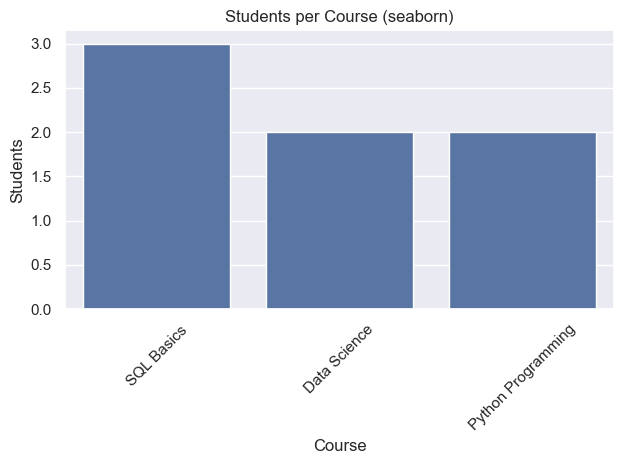
6.6 Grade distribution per course (counts and proportions)
q_dist = """
SELECT c.course_name, g.grade, COUNT(*) AS count
FROM courses c
JOIN grades g ON c.id = g.course_id
GROUP BY c.course_name, g.grade
ORDER BY c.course_name, g.grade;
"""
df_dist = pd.read_sql(q_dist, engine)
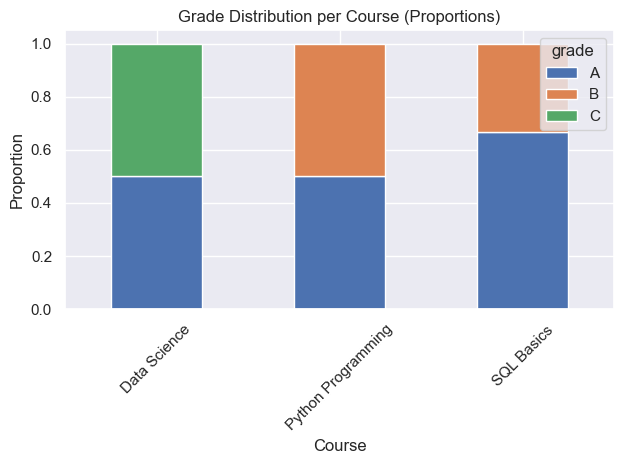
display(df_dist)| course_name | grade | count | |
|---|---|---|---|
| 0 | Data Science | A | 1 |
| 1 | Data Science | C | 1 |
| 2 | Python Programming | A | 1 |
| 3 | Python Programming | B | 1 |
| 4 | SQL Basics | A | 2 |
| 5 | SQL Basics | B | 1 |
Matplotlib — stacked bars (counts & proportions)
# Pivot: rows=courses, cols=grades (A/B/C), values=count
wide = df_dist.pivot(index="course_name", columns="grade", values="count").fillna(0)
# Counts (stacked)
ax = wide.plot(kind="bar", stacked=True)
ax.set_title("Grade Distribution per Course (Counts)")
ax.set_xlabel("Course")
ax.set_ylabel("Count")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
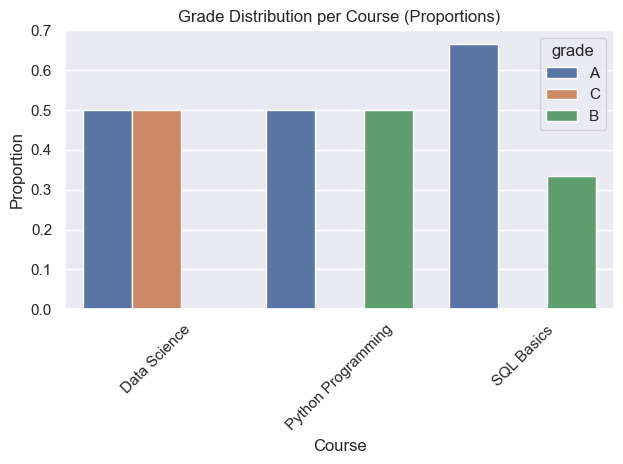
# Proportions (stacked)
prop = wide.div(wide.sum(axis=1), axis=0)
ax = prop.plot(kind="bar", stacked=True)
ax.set_title("Grade Distribution per Course (Proportions)")
ax.set_xlabel("Course")
ax.set_ylabel("Proportion")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()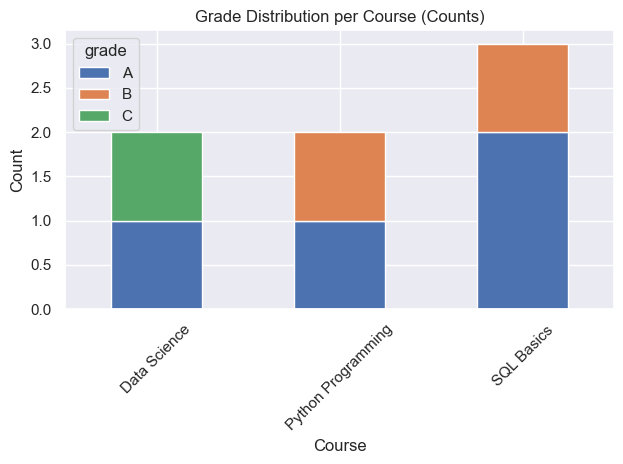
Seaborn — grouped bars (optional)
if sns:
# Grouped bars: grade on hue, course on x
ax = sns.barplot(data=df_dist, x="course_name", y="count", hue="grade")
ax.set_title("Grade Distribution per Course (Counts)")
ax.set_xlabel("Course")
ax.set_ylabel("Count")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# Proportions: compute per-course percentages first (long form for seaborn)
df_prop = (df_dist
.assign(total=df_dist.groupby("course_name")["count"].transform("sum"))
.assign(prop=lambda d: d["count"] / d["total"]))
ax = sns.barplot(data=df_prop, x="course_name", y="prop", hue="grade")
ax.set_title("Grade Distribution per Course (Proportions)")
ax.set_xlabel("Course")
ax.set_ylabel("Proportion")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()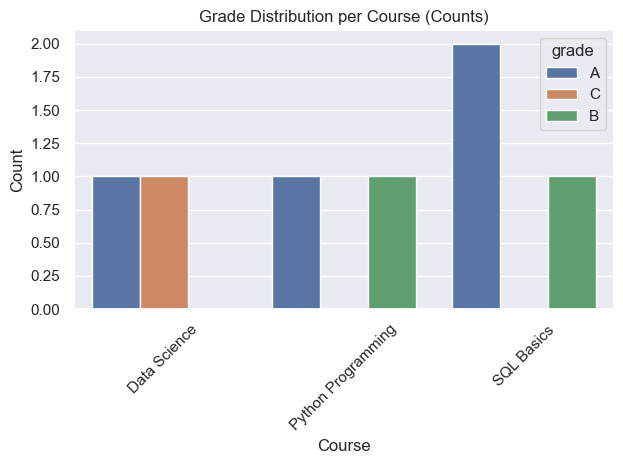
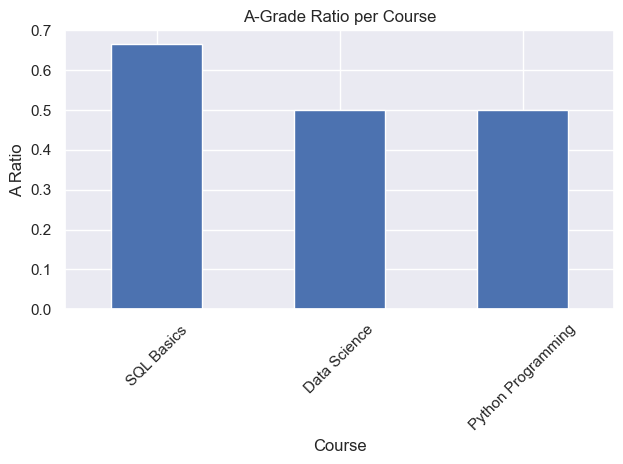
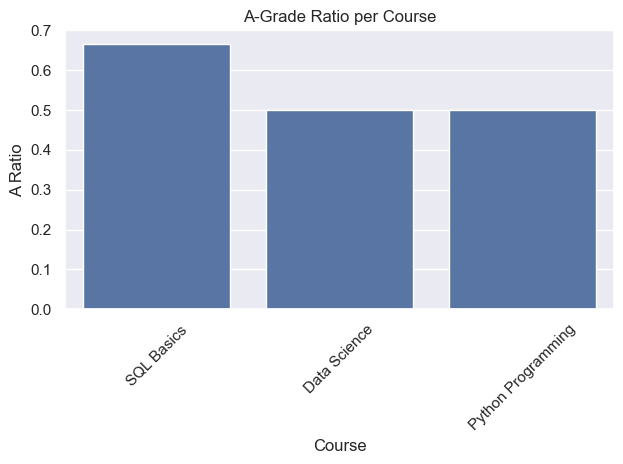
6.7 A-grade ratio per course
q_ratio = """
SELECT c.course_name,
SUM(CASE WHEN g.grade='A' THEN 1 ELSE 0 END) AS num_A,
COUNT(*) AS total
FROM courses c
JOIN grades g ON c.id = g.course_id
GROUP BY c.course_name
ORDER BY num_A DESC;
"""
df_ratio = pd.read_sql(q_ratio, engine)
df_ratio["A_ratio"] = df_ratio["num_A"] / df_ratio["total"]
display(df_ratio)
# matplotlib
ax = df_ratio.plot(kind="bar", x="course_name", y="A_ratio", legend=False)
ax.set_title("A-Grade Ratio per Course")
ax.set_xlabel("Course")
ax.set_ylabel("A Ratio")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# seaborn (optional)
if sns:
ax = sns.barplot(data=df_ratio, x="course_name", y="A_ratio")
ax.set_title("A-Grade Ratio per Course")
ax.set_xlabel("Course")
ax.set_ylabel("A Ratio")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()| course_name | num_A | total | A_ratio | |
|---|---|---|---|---|
| 0 | SQL Basics | 2.0 | 3 | 0.666667 |
| 1 | Data Science | 1.0 | 2 | 0.500000 |
| 2 | Python Programming | 1.0 | 2 | 0.500000 |
6.8 Export results
import os
os.makedirs("data", exist_ok=True) # create folder if missing
df_counts.to_csv("data/students_per_course.csv", index=False)
wide.to_csv("data/grade_distribution_counts.csv")
prop.to_csv("data/grade_distribution_proportions.csv")
df_ratio.to_csv("data/a_grade_ratio.csv", index=False)
print("✅ Saved 4 CSVs to the data/ folder.")✅ Saved 4 CSVs to the data/ folder.6.9 ✅ Learning Outcome
By the end of this Q&A, you will be able to:
- Load CSV files into MySQL/MariaDB using either phpMyAdmin or
LOAD DATA LOCAL INFILE - Design relational tables (
students,courses,grades) and enforce relationships with foreign keys - Write and run JOIN and GROUP BY queries to analyze course enrollments and grade distributions
- Validate imports with sanity checks (
COUNT(*),JOINqueries) before analysis - Export query results and create visualizations in Python using pandas and matplotlib (or seaborn)